SLURM, A Highly Scalable Workload Manager
Slurm is an open-source cluster resource management and job scheduling system.
Slurm has three key features:
- Resources Scheduling: Allocation of exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time.
- Workload Management: Ability to start, execute and monitor parallel jobs.
- Queue Management: Efficient handling of pending work by using the backfill scheduling algorithm.
Architecture
The architecture is the following:
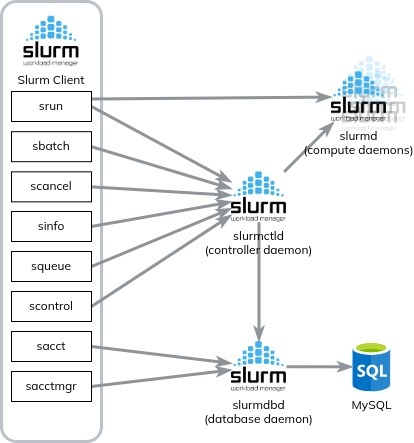
The client/login node can send commands to the Slurm controller daemon (slurmctld) (and directly to a compute node in case of a srun job). Each controller manages a cluster of computer nodes (slurmd).
Finally, there is eventually a slurm database daemon (slurmdbd) to manage the accounting data.
The main commands to know are the following:
srun: submit and execute a job in real-time. The job can be interactive too (similarly todocker run -it)!sbatch: submit a job script for later execution. The script contains one or more srun commands to launch parallel tasks.scancel: cancel a job.sinfo: reports the state of partitions (group of nodes) and nodes of a cluster.squeue: reports the state of the jobs.scontrol: modify the Slurm cluster state (can only be run by root).sacct: reports the jobs accounting information from the Slurm database.sacctmgr: modify the Slurm database, including Slurm account information
Why Slurm ?
By itself, Slurm can be replaced with solutions like Torque, Spectrum LSF, or even the Kubernetes Scheduler.
The reason we are using Slurm is mainly because of the support of plugins, more precisely NVIDIA Pyxis SPANK plugin. Pyxis uses NVIDIA Enroot to run Slurm jobs with Docker/Singularity images.
NVIDIA Enroot is very similar to Docker. The main difference is that it runs containers (and OS images) in unprivileged sandboxes. Enroot also has built-in GPU support, which means we can run Slurm tasks with container images designed for GPUs (like Tensorflow, NVIDIA container images).
The resource management feature of Slurm is also quite powerful to make sure users doesn't consume too many resources.
However, although Slurm is powerful, it has its drawbacks. For example, the REST API is not stable and the documentation is not precise enough for a user-friendly experience. Also, since Slurm is programmed in C, we had problems with memory leaks (which were fixed in version 21.08.7).
OAR, a job scheduler based on Perl (the v3 will be based on Python), could be a valid alternative/addition.