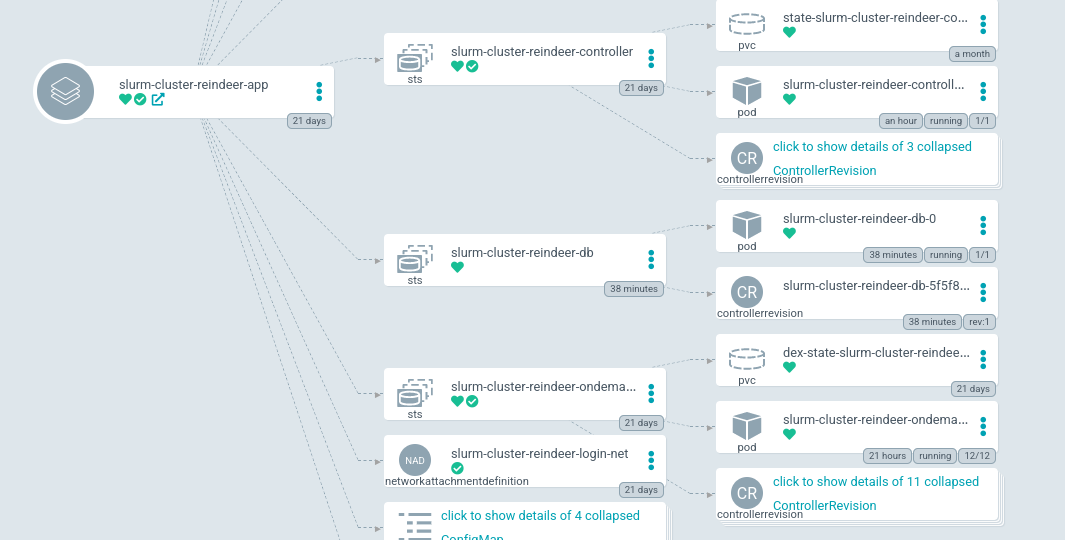
Deploying SLURM Cluster
Deploying the SLURM database isn't stable yet. Please feel free to create an issue so we can improve its stability.
Helm and Docker resources
The Helm resources are stored on the ClusterFactory Git Repository.
The Dockerfile is described in the git repository deepsquare-io/slurm-docker.
The Docker images can be pulled with:
docker pull ghcr.io/deepsquare-io/slurm:latest-controller
docker pull ghcr.io/deepsquare-io/slurm:latest-login
docker pull ghcr.io/deepsquare-io/slurm:latest-db
docker pull ghcr.io/deepsquare-io/slurm:latest-rest
You should always verify the default Helm values before editing the values field of an Argo CD Application.
1. Preparation
Compared to the other guides we will start from scratch.
Delete the argo/slurm-cluster directory (or rename it).
Deploying a SLURM cluster isn't easy and you MUST have these components ready:
- A LDAP server and a SSSD configuration, to synchronize the user ID across the cluster
- A MySQL server for the SLURM DB
- A JWT private key, for the authentication via REST API
- A MUNGE key, for the authentication of SLURM daemons
Namespace and AppProject
Create and apply the Namespace and AppProject:
apiVersion: v1
kind: Namespace
metadata:
name: slurm-cluster
labels:
app.kubernetes.io/name: slurm-cluster
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: slurm-cluster
namespace: argocd
# Finalizer that ensures that project is not deleted until it is not referenced by any application
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
description: Slurm cluster
# Allow manifests to deploy from any Git repos
sourceRepos:
- '*'
# Only permit applications to deploy to the namespace in the same cluster
destinations:
- namespace: slurm-cluster
server: https://kubernetes.default.svc
namespaceResourceWhitelist:
- kind: '*'
group: '*'
clusterResourceWhitelist:
- kind: '*'
group: '*'
kubectl apply -f argo/slurm-cluster/
LDAP deployment
-
Follow the guide.
-
Open a shell on the LDAP server container and create a user and a group
slurm:
# Create user
dsidm -b "dc=example,dc=com" localhost user create \
--uid slurm \
--cn slurm \
--displayName slurm \
--homeDirectory "/dev/shm" \
--uidNumber 1501 \
--gidNumber 1501
# Create group
dsidm -b "dc=example,dc=com" localhost group create \
--cn slurm
# Add posixGroup property and gidNumber
dsidm -b "dc=example,dc=com" localhost group modify slurm \
"add:objectClass:posixGroup" \
"add:gidNumber:1501"
SSSD configuration
Let's store it in a Secret:
- Create the
argo/slurm-cluster/secrets/directory and create a-secret.yaml.localfile:
apiVersion: v1
kind: Secret
metadata:
name: sssd-secret
namespace: slurm-cluster
type: Opaque
stringData:
sssd.conf: |
# https://sssd.io/docs/users/troubleshooting/how-to-troubleshoot-backend.html
[sssd]
services = nss,pam,sudo,ssh
config_file_version = 2
domains = example-ldap
[sudo]
[nss]
[pam]
offline_credentials_expiration = 60
[domain/example-ldap]
debug_level=3
cache_credentials = True
dns_resolver_timeout = 15
override_homedir = /home/ldap-users/%u
id_provider = ldap
auth_provider = ldap
access_provider = ldap
chpass_provider = ldap
ldap_schema = rfc2307bis
ldap_uri = ldaps://dirsrv-389ds.ldap.svc.cluster.local:3636
ldap_default_bind_dn = cn=Directory Manager
ldap_default_authtok = <password>
ldap_search_timeout = 50
ldap_network_timeout = 60
ldap_user_member_of = memberof
ldap_user_gecos = cn
ldap_user_uuid = nsUniqueId
ldap_group_uuid = nsUniqueId
ldap_search_base = ou=people,dc=example,dc=com
ldap_group_search_base = ou=groups,dc=example,dc=com
ldap_sudo_search_base = ou=sudoers,dc=example,dc=com
ldap_user_ssh_public_key = nsSshPublicKey
ldap_account_expire_policy = rhds
ldap_access_order = filter, expire
ldap_access_filter = (objectClass=posixAccount)
ldap_tls_cipher_suite = HIGH
# On Ubuntu, the LDAP client is linked to GnuTLS instead of OpenSSL => cipher suite names are different
# In fact, it's not even a cipher suite name that goes here, but a so called "priority list" => see $> gnutls-cli --priority-list
# See https://backreference.org/2009/11/18/openssl-vs-gnutls-cipher-names/ , gnutls-cli is part of package gnutls-bin
Adapt this secret based on your LDAP configuration.
- Seal the secret:
cfctl kubeseal
- Apply the SealedSecret:
kubectl apply -f argo/slurm-cluster/secrets/sssd-sealed-secret.yaml
MySQL deployment
You can deploy MySQL using the Helm Chart of Bitnami and deploy it with ArgoCD.
After deploying the MySQL/MariaDB server, you must create a slurm database. Open a shell on the MySQL container and run:
mysql -u root -p -h localhost
# Enter your root password
create user 'slurm'@'%' identified by '<your password>';
grant all on slurm_acct_db.* TO 'slurm'@'%';
create database slurm_acct_db;
JWT Key generation
ssh-keygen -t rsa -b 4096 -m PEM -f jwtRS256.key
Let's store it in a Secret:
- Create a
-secret.yaml.localfile:
apiVersion: v1
kind: Secret
metadata:
name: slurm-secret
namespace: slurm-cluster
type: Opaque
stringData:
jwt_hs256.key: |
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
- Seal the secret:
cfctl kubeseal
- Apply the SealedSecret:
kubectl apply -f argo/slurm-cluster/secrets/slurm-sealed-secret.yaml
MUNGE Key generation
# As root
dnf install -y munge
/usr/sbin/create-munge-key
cat /etc/munge/munge.key | base64
Let's store it in a Secret:
- Create a
-secret.yaml.localfile:
apiVersion: v1
kind: Secret
metadata:
name: munge-secret
namespace: slurm-cluster
type: Opaque
data:
munge.key: |
<base 64 encoded key>
- Seal the secret:
cfctl kubeseal
- Apply the SealedSecret:
kubectl apply -f argo/cvmfs/secrets/munge-sealed-secret.yaml
2. Begin writing the slurm-cluster-<cluster name>-app.yaml
2.a. Argo CD Application configuration
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: slurm-cluster-<FILL ME: cluster name>-app
namespace: argocd
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
project: slurm-cluster
source:
# You should have forked this repo. Change the URL to your fork.
repoURL: git@github.com:<FILL ME: your account>/ClusterFactory.git
# You should use your branch too.
targetRevision: HEAD
path: helm/slurm-cluster
helm:
releaseName: slurm-cluster-<FILL ME: cluster name>
valueFiles:
- values-<FILL ME: cluster name>.yaml
destination:
server: 'https://kubernetes.default.svc'
namespace: slurm-cluster
syncPolicy:
automated:
prune: true # Specifies if resources should be pruned during auto-syncing ( false by default ).
selfHeal: true # Specifies if partial app sync should be executed when resources are changed only in target Kubernetes cluster and no git change detected ( false by default ).
allowEmpty: false # Allows deleting all application resources during automatic syncing ( false by default ).
syncOptions: []
retry:
limit: 5 # number of failed sync attempt retries; unlimited number of attempts if less than 0
backoff:
duration: 5s # the amount to back off. Default unit is seconds, but could also be a duration (e.g. "2m", "1h")
factor: 2 # a factor to multiply the base duration after each failed retry
maxDuration: 3m # the maximum amount of time allowed for the backoff strategy
2.b. Values: Configuring the SLURM cluster
Add:
sssd:
secretName: sssd-secret
munge:
secretName: munge-secret
jwt:
secretName: slurm-secret
slurmConfig:
clusterName: <FILL ME: cluster-name>
compute:
srunPortRangeStart: 60001
srunPortRangeEnd: 63000
debug: debug5
accounting: |
AccountingStorageType=accounting_storage/slurmdbd
AccountingStorageHost=slurm-cluster-<FILL ME: cluster name>.slurm-cluster.svc.cluster.local
AccountingStoragePort=6819
AccountingStorageTRES=gres/gpu
controller:
parameters: enable_configless
debug: debug5
defaultResourcesAllocation: |
# Change accordingly
DefCpuPerGPU=4
DefMemPerCpu=7000
nodes: |
# Change accordingly
NodeName=cn[1-12] CPUs=32 Boards=1 SocketsPerBoard=1 CoresPerSocket=16 ThreadsPerCore=2 RealMemory=128473 Gres=gpu:4
partitions: |
# Change accordingly
PartitionName=main Nodes=cn[1-12] Default=YES MaxTime=INFINITE State=UP OverSubscribe=NO TRESBillingWeights="CPU=2.6,Mem=0.25G,GRES/gpu=24.0"
gres: |
# Change accordingly
NodeName=cn[1-12] File=/dev/nvidia[0-3] AutoDetect=nvml
# Extra slurm.conf configuration
extra: |
LaunchParameters=enable_nss_slurm
DebugFlags=Script,Gang,SelectType
TCPTimeout=5
# MPI stacks running over Infiniband or OmniPath require the ability to allocate more
# locked memory than the default limit. Unfortunately, user processes on login nodes
# may have a small memory limit (check it by ulimit -a) which by default are propagated
# into Slurm jobs and hence cause fabric errors for MPI.
PropagateResourceLimitsExcept=MEMLOCK
ProctrackType=proctrack/cgroup
TaskPlugin=task/cgroup
SwitchType=switch/none
MpiDefault=pmix_v2
ReturnToService=2
GresTypes=gpu
PreemptType=preempt/qos
PreemptMode=REQUEUE
PreemptExemptTime=-1
Prolog=/etc/slurm/prolog.d/*
Epilog=/etc/slurm/epilog.d/*
# Federation
FederationParameters=fed_display
3. Slurm DB Deployment
3.a. Secrets
Assuming you have deployed LDAP and MySQL, we will store the slurmdbd.conf inside a secret:
- Create a
-secret.yaml.localfile:
apiVersion: v1
kind: Secret
metadata:
name: slurmdbd-conf-secret
namespace: slurm-cluster
type: Opaque
stringData:
slurmdbd.conf: |
# See https://slurm.schedmd.com/slurmdbd.conf.html
### Main
DbdHost=slurm-cluster-<FILL ME: cluster name>-db-0
SlurmUser=slurm
### Logging
DebugLevel=debug5 # optional, defaults to 'info'. Possible values: fatal, error, info, verbose, debug, debug[2-5]
LogFile=/var/log/slurm/slurmdbd.log
PidFile=/var/run/slurmdbd.pid
LogTimeFormat=thread_id
AuthAltTypes=auth/jwt
AuthAltParameters=jwt_key=/var/spool/slurm/jwt_hs256.key
### Database server configuration
StorageType=accounting_storage/mysql
StorageHost=<FILL ME>
StorageUser=<FILL ME>
StoragePass=<FILL ME>
Replace the <FILL ME> according to your existing configuration.
- Seal the secret:
cfctl kubeseal
- Apply the SealedSecret:
kubectl apply -f argo/slurm-cluster/secrets/slurmdbd-conf-sealed-secret.yaml
3.b. Values: Enable SLURM DB
Edit the elm/slurm-cluster/values-<cluster name>.yaml values
Let's add the values to deploy a SLURM DB.
db:
enabled: true
config:
secretName: slurmdbd-conf-secret
If you are using LDAPS and the CA is private:
db:
enabled: true
config:
secretName: slurmdbd-conf-secret
command: ['sh', '-c', 'update-ca-trust && /init']
volumeMounts:
- name: ca-cert
mountPath: /etc/pki/ca-trust/source/anchors/example.com.ca.pem
subPath: example.com.ca.pem
volumes:
- name: ca-cert
secret:
secretName: local-ca-secret
local-ca-secret is a Secret containing example.com.ca.pem.
You can already deploy it:
git add .
git commit -m "Added SLURM DB values"
git push
# This is optional if the application is already deployed.
kubectl apply -f argo/slurm-cluster/apps/slurm-cluster-<cluster name>-app.yaml
The service should be accessible at the address slurm-cluster-<cluster name>-db-0.slurm-cluster.svc.cluster.local. Use that URL in the slurm config.
4. Slurm Controller Deployment
4.a. Values: Enable SLURM Controller
Let's add the values to deploy a SLURM Controller.
controller:
enabled: true
persistence:
storageClassName: 'dynamic-nfs'
accessModes: ['ReadWriteOnce']
size: 10Gi
nodeSelector:
topology.kubernetes.io/region: <FILL ME> # <country code>-<city>
topology.kubernetes.io/zone: <FILL ME> # <country code>-<city>-<index>
resources:
requests:
cpu: '250m'
memory: '1Gi'
limits:
cpu:
memory: '1Gi'
Notice that kubernetes.io/hostname is used, this is because the slurm controller will be using the host network and we don't want to make the slurm controller move around.
We might develop a HA setup in the future version of ClusterFactory.
If you are using LDAPS and the CA is private, append these values:
controller:
# ...
command: ['sh', '-c', 'update-ca-trust && /init']
volumeMounts:
- name: ca-cert
mountPath: /etc/pki/ca-trust/source/anchors/example.com.ca.pem
subPath: example.com.ca.pem
volumes:
- name: ca-cert
secret:
secretName: local-ca-secret
local-ca-secret is a Secret containing example.com.ca.pem.
You can already deploy it:
git add .
git commit -m "Added SLURM Controller values"
git push
# This is optional if the application is already deployed.
kubectl apply -f argo/slurm-cluster/apps/slurm-cluster-<cluster name>-app.yaml
The SLURM controller is in host mode using hostPort so it can communicate with the bare-metal hosts. There
is also a SLURM controller Service running for the internal communication with Slurm DB and Slurm Login.
4.c Testing: sinfo from the controller node
You should be able to run a kubectl exec session on the controller node and execute sinfo:
[user@local /]> kubectl exec -it -n slurm-cluster slurm-cluster-<cluster-name>-controller-0 -c slurm-cluster-<cluster-name>-controller -- bash
[root@slurm-cluster-reindeer-controller-0 /]> sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
main* up infinite 12 down* cn[1-12]
5. Slurm Compute Bare-Metal Deployment
5.a. Build an OS Image with Slurm
We have enabled config-less in the slurm.conf.
We need to build an OS Image with Slurm Daemon installed.
Install these packages:
pmix4
slurm
slurm-contribs
slurm-libpmi
slurm-pam_slurm
slurm-slurmd
libnvidia-container1
libnvidia-container-tools
enroot-hardened
enroot-hardened+caps
nvslurm-plugin-pyxis
from the DeepSquare YUM repository.
5.b. Postscripts
Next, you have to configure a service by using a postscript.
The service:
[Unit]
Description=Slurm node daemon
After=network.target munge.service
[Service]
Type=forking
ExecStartPre=/usr/bin/id slurm
Restart=always
RestartSec=3
ExecStart=/usr/sbin/slurmd -d /usr/sbin/slurmstepd --conf-server slurm-cluster-<cluster name>-controller-0.example.com
ExecReload=/bin/kill -HUP $MAINPID
PIDFile=/var/run/slurmd.pid
KillMode=process
LimitNOFILE=51200
LimitMEMLOCK=infinity
LimitSTACK=infinity
[Install]
WantedBy=multi-user.target
Add slurm-cluster-<cluster name>-controller-0.example.com to the CoreDNS configuration.
If you are using a hostPort, put the IP of the Kubernetes host hosting the pod. If you are using a LoadBalancer, put the IP you've given to the LoadBalancer. If you are using IPVLAN, put the IP you've given to the IPVLAN.
A simple postbootscript:
#!/bin/sh -ex
# Copy the CA certificate created for the private-cluster-issuer
cp ./certs/my-ca.prem /etc/pki/ca-trust/source/anchors/my-ca.pem
mkdir -p /var/log/slurm/
cat <<\END | base64 -d >/etc/munge/munge.key
...
END
chmod 600 /etc/munge/munge.key
cat <<\END >/etc/sssd/sssd.conf
...
END
chmod 600 /etc/sssd/sssd.conf
#-- Add enroot extra hooks for PMIx and PyTorch multi-node support
cp /usr/share/enroot/hooks.d/50-slurm-pmi.sh /usr/share/enroot/hooks.d/50-slurm-pytorch.sh /etc/enroot/hooks.d
# Enable Pyxis (container jobs)
cat <<\END >/etc/slurm/plugstack.conf.d/
optional /usr/lib64/slurm/spank_pyxis.so runtime_path=/run/pyxis container_scope=job
END
cat <<\END >/etc/systemd/system/slurmd.service
[Unit]
Description=Slurm node daemon
After=network.target munge.service remote-fs.target
Wants=network-online.target
[Service]
Type=simple
Restart=always
RestartSec=3
ExecStart=/usr/sbin/slurmd -d /usr/sbin/slurmstepd --conf-server <node host IP>
ExecReload=/bin/kill -HUP $MAINPID
PIDFile=/var/run/slurmd.pid
KillMode=process
LimitNOFILE=131072
LimitMEMLOCK=infinity
LimitSTACK=infinity
Delegate=yes
StandardOutput=null
StandardError=null
[Install]
WantedBy=multi-user.target
END
#-- Wait for LDAP
update-ca-trust
systemctl restart sssd
while ! id slurm
do
sleep 1
done
systemctl daemon-reload
systemctl restart munge
systemctl enable slurmd
systemctl start --no-block slurmd
After setup SLURM, you should also:
- Mount the home directory of the LDAP users (probably like
/home/ldap-users) - Use the postscript to configure SSSD
- Use the postscript to import the
munge.key
In the order:
- Check your journal (
journalctl) and check the logs. - Stuck in a
id slurmloop ?- Check the SSSD configuration
- Check the TLS certificate
- Check if Traefik and LDAP ports (
nc -vz <LB IP> <LDAP PORT>)
- SSSD is working (
id slurmshows 1501 as UID), butsinfois crashing- Check the health of your SLURM controller pod
- Check if the ports of the SLURM controller (
nc -vz <SLURM CTL IP> 6817) - Check if the domain name of the SLURM controller can be received (
dig @<DNS SERVER IP> slurm-cluster-<cluster name>-controller-0.example.com) - Check the DNS client configuration (
/etc/resolv.conf)
- Slurm is crashing but not
sinfo- Check
/var/log/slurm/slurm.log
- Check
5.c. Reboot the nodes
If the controller is running, the nodes should automatically receive the slurm.conf inside /run/slurm/conf.
6. Slurm Login Deployment
6.a. Secrets and Volumes
SSH Server configuration
The login nodes can be exposed to the external network using Multus CNI and the IPVLAN plugin. This is to expose the srunPortRange and the SSH port.
If you don't plan to use srun and prefer sbatch, we recommend to use a simple Kubernetes Service to expose the login nodes.
Thanks to SSSD, the users can log in to the nodes using SSH using the passwords stored in LDAP.
We have to generate the SSH host keys:
yes 'y' | ssh-keygen -N '' -f ./ssh_host_rsa_key -t rsa -C login-node
yes 'y' | ssh-keygen -N '' -f ./ssh_host_ecdsa_key -t ecdsa -C login-node
yes 'y' | ssh-keygen -N '' -f ./ssh_host_ed25519_key -t ed25519 -C login-node
6 files will be generated. We will also add our sshd_config.
- Create a
-secret.yaml.localfile:
apiVersion: v1
kind: Secret
metadata:
name: login-sshd-secret
namespace: slurm-cluster
type: Opaque
stringData:
ssh_host_ecdsa_key: |
-----BEGIN OPENSSH PRIVATE KEY-----
<FILL ME>
-----END OPENSSH PRIVATE KEY-----
ssh_host_ecdsa_key.pub: |
ecdsa-sha2-nistp256 <FILL ME>
ssh_host_ed25519_key: |
-----BEGIN OPENSSH PRIVATE KEY-----
<FILL ME>
-----END OPENSSH PRIVATE KEY-----
ssh_host_ed25519_key.pub: |
ssh-ed25519 <FILL ME>
ssh_host_rsa_key: |
-----BEGIN OPENSSH PRIVATE KEY-----
<FILL ME>
-----END OPENSSH PRIVATE KEY-----
ssh_host_rsa_key.pub: |
ssh-rsa <FILL ME>
sshd_config: |
Port 22
AddressFamily any
ListenAddress 0.0.0.0
ListenAddress ::
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
PermitRootLogin prohibit-password
PasswordAuthentication yes
# Change to yes to enable challenge-response passwords (beware issues with
# some PAM modules and threads)
ChallengeResponseAuthentication no
UsePAM yes
X11Forwarding yes
PrintMotd no
AcceptEnv LANG LC_*
# override default of no subsystems
Subsystem sftp /usr/lib/openssh/sftp-server
AuthorizedKeysCommand /usr/bin/sss_ssh_authorizedkeys
AuthorizedKeysCommandUser root
Replace the <FILL ME> with the values based on the generated files.
- Seal the secret:
cfctl kubeseal
- Apply the SealedSecret:
kubectl apply -f argo/slurm-cluster/secrets/login-sshd-sealed-secret.yaml
Home directory for the LDAP users
If you have configured your LDAP server, you might have to change the homeDirectory to something like /home/ldap-users.
You must mount the home directory of the LDAP users using NFS.
DO NOT use StorageClass since the provisioning is static. We don't want to create a volume per replica. There is only one common volume.
apiVersion: v1
kind: PersistentVolume
metadata:
name: ldap-users-<cluster name>-pv
namespace: slurm-cluster
labels:
app: slurm-login
topology.kubernetes.io/region: <FILL ME> # <country code>-<city>
topology.kubernetes.io/zone: <FILL ME> # <country code>-<city>-<index>
spec:
capacity:
storage: 1000Gi
mountOptions:
- hard
- nfsvers=4.1
- noatime
- nodiratime
csi:
driver: nfs.csi.k8s.io
readOnly: false
volumeHandle: <unique id> # uuidgen
volumeAttributes:
server: <FILL ME> # IP or host
share: <FILL ME> # /srv/nfs/k8s/ldap-users
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ldap-users-<cluster name>-pvc
namespace: slurm-cluster
labels:
app: slurm-login
topology.kubernetes.io/region: <FILL ME> # <country code>-<city>
topology.kubernetes.io/zone: <FILL ME> # <country code>-<city>-<index>
spec:
volumeName: ldap-users-<cluster name>-pv
accessModes: [ReadWriteMany]
storageClassName: ''
resources:
requests:
storage: 1000Gi
Apply the PV and PVC:
kubectl apply -f argo/slurm-cluster/volumes/ldap-users-<cluster name>-pv.yaml
6.b. Values: Enable SLURM Login
login:
enabled: true
replicas: 1
sshd:
secretName: login-sshd-secret
nodeSelector:
topology.kubernetes.io/region: <FILL ME> # <country code>-<city>
topology.kubernetes.io/zone: <FILL ME> # <country code>-<city>-<index>
# Extra volume mounts
volumeMounts:
- name: ldap-users-pvc
mountPath: /home/ldap-users
# Extra volumes
volumes:
- name: ldap-users-pvc
persistentVolumeClaim:
claimName: ldap-users-<cluster name>-pvc
service:
enabled: true
type: ClusterIP
# Use LoadBalancer to expose via MetalLB
# type: LoadBalancer
# annotations:
# metallb.universe.tf/address-pool: slurm-ch-basel-1-pool
# Expose via IPVLAN, can be unstable.
# Using IPVLAN permits srun commands.
net:
enabled: false
# Kubernetes host interface
type: ipvlan
masterInterface: eth0
mode: l2
# https://www.cni.dev/plugins/current/ipam/static/
ipam:
type: static
addresses:
- address: 192.168.0.20/24
gateway: 192.168.0.1
Edit the values accordingly.
Service or IPVLan?
A Kubernetes Service offers a lot of advantages while IPVLan offers a solution to a problem.
It is extremely recommended to use a Kubernetes service to expose your connection node as it provides load balancing and is easy to configure.
| Kubernetes LoadBalancer Service | Multus CNI |
|---|---|
| A LoadBalancer service provides limited control over networking, as it only provides a single IP address for a Kubernetes service. | IPVLan with Multus allows you to have more fine-grained control over networking by enabling you to use multiple network interfaces in a pod, each with its own IP address and route table. |
| A LoadBalancer service is a simple and straightforward way to expose a Kubernetes service to the internet. | Setting up IPVLan with Multus can be more complex than using a simple LoadBalancer service, as it requires more configuration and setup time. |
| A LoadBalancer service can only expose a set of ports. | Using IPVLan with Multus will allow a pod to directly connect to the host network. |
As a result, using a Kubernetes LoadBalancer service will render the Slurm srun commands inoperable (although sbatch will work and is the preferred method for job submission). On the other hand, adopting Multus CNI eliminates the load balancing feature, but could lead to instability.
Because k8s-pod-network is the default network, you must write routes to your networks.
For example, if we have two sites 10.10.0.0/24 and 10.10.1.0/24, you would write:
ipam:
type: static
addresses:
- address: 192.168.0.20/24
gateway: 192.168.0.1
routes:
- dst: 10.10.1.0/24
If we kubectl exec to the container and run ip route, you would see:
# ip route
default via 169.254.1.1 dev eth0
10.10.0.0/24 via 10.10.0.1 dev net1
10.10.1.0/24 via 10.10.0.1 dev net1
169.254.1.1 dev eth0 scope link
10.10.0.0/20 via 10.10.0.1 dev net1
10.10.0.0/20 dev net1 proto kernel scope link src 10.10.0.21
The issue is tracked at deepsquare-io/ClusterFactory#29 and projectcalico/calico#5199.
If you are using LDAPS and the CA is private, add these values:
login:
# ...
command: ['sh', '-c', 'update-ca-trust && /init']
volumeMounts:
- name: ldap-users-pvc
mountPath: /home/ldap-users
- name: ca-cert
mountPath: /etc/pki/ca-trust/source/anchors/example.com.ca.pem
subPath: example.com.ca.pem
volumes:
- name: ldap-users-pvc
persistentVolumeClaim:
claimName: ldap-users-<cluster name>-pvc
- name: ca-cert
secret:
secretName: local-ca-secret
local-ca-secret is a Secret containing example.com.ca.pem.
You can deploy it:
git add .
git commit -m "Added SLURM Login values"
git push
# This is optional if the application is already deployed.
kubectl apply -f argo/slurm-cluster/apps/slurm-cluster-<cluster name>-app.yaml
6.c Testing: Access to a SLURM Login node
Because the container is exposed to the external network, you should be able to ssh directly to the login node.
ssh user@login-node
If the LDAP User user exists, the login node should be asking for a password.